Member-only story
Postgres Partitions
There is a common misconception that partitioning a table in Postgres will improve performance, while it’s true in some cases, but sometimes partitioning may actually degrade your performance if done incorrectly.
Let me try to give a very brief overview about postgres partitioning in general and some guideline to consider before partitioning the table.
Introduction to Partitions
In simple terms, partitioning is simply splitting a large table and its corresponding indexes into smaller physical tables and indexes.
For the sake of simplicity, let’s consider only B-Tree index in this blog, but the problems and guidelines described in this blog will be applicable to other types of indexes as well.
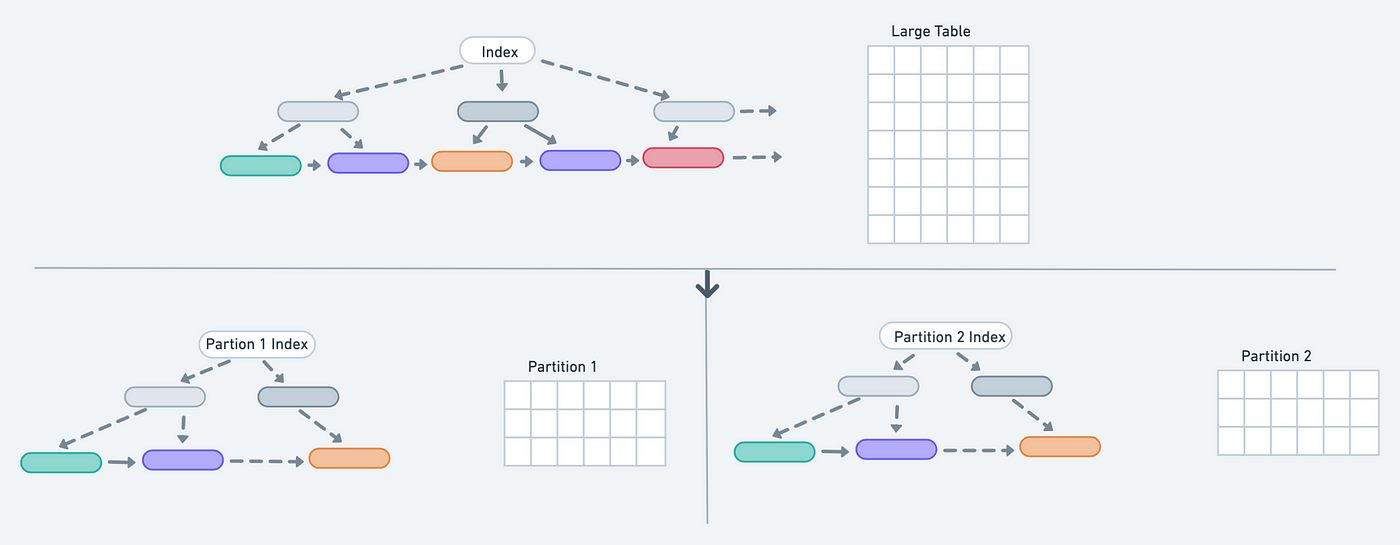
Before discussing further about partitions, it’s worth to highlight that most index implementation will be a variant of B-Tree and the size of each node in the tree is usually the operating system’s page size- this allows postgres to perform disk read/writes efficiently as operating system calls usually transfer one page at a time from disk to memory and vice versa for every read/write.
Types of Partitions
Postgres offers 3 types of partitioning- Range, List & Hash
In order to demonstrate the different types of partitions, let’s take an example of a payment application which stores every single transaction as a row in the Transaction table
Range Partitions
A classic example of range partition is to divide the table by date ranges, i.e., you could create one partition for every single month as shown in the below example.

Performance of range partitions
In the above example, writes will be faster as each insert/update touches one smaller table, also any index re-structuring will also be faster as we are now working with one…

